쿠버네티스
쿠버네티스는 구글에서 만든 컨테이너 오케스트레이션 오픈소스 플랫폼으로, 분산된 여러 서버에 여러 컨테이너 애플리케이션을 쉽게 배포하고 관리할 수 있도록 하는 환경을 만들기 위해 쿠버네티스를 사용한다.
그럼 쿠버네티스에서는 어떻게 분산된 여러 서버에 컨테이너 애플리케이션을 배포하고 관리할까?
클러스터
쿠버네티스는 컨테이너 애플리케이션을 배포할 여러 서버들을 하나의 클러스터로써 관리한다. 쿠버네티스에서는 클러스터로 묶은 서버들을 노드라고 부른다. 그리고 노드의 종류로는 컨트롤 플레인 노드와 워커 노드가 있다.

워커 노드 는 실제로 쿠버네티스에 배포된 애플리케이션이 구동되는 노드이고, 컨트롤 플레인 노드는 워커노드와 컨테이너 애플리케이션 등 쿠버네티스 전체를 관리하는 역할을 한다. 그리고 각 노드에서는 쿠버네티스를 관리하거나 컨테이너 애플리케이션을 배포하는 역할을 하는 컴포넌트들이 배치되어 있다.
컨트롤 플레인 노드 컴포넌트
컨트롤 플레인 노드의 컴포넌트는 클러스터에 관한 전반적인 관리를 수행하고, 클러스터 이벤트를 감지하고 반응한다. (파드가 생성되면 어떤 노드에 파드를 배치할지 결정 등등..) 컨트롤 플레인 컴포넌트의 종류로는 아래와 같다.
- kube-apiserver: 쿠버네티스 API 요청을 받는 컨트롤 플레인 컴포넌트
- etcd: 모든 클러스터 데이터를 담는 key-value 기반 저장소
- kube-scheduler: 노드가 배정되지 않은 새로 생성된 파드를 감지하고 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트
- kube-controller-manager: 컨트롤러 프로세스를 실행하는 컨트롤 플레인 컴포넌트
- cloud-controller-manager: 클라우드별 컨트롤 로직을 포함하는 컨트롤 플레인 컴포넌트
노드 공통 컴포넌트
컨트롤 플레인을 포함한 모든 노드 컴포넌트는 노드에서 동작 중인 파드를 유지시키며, 쿠버네티스 런타임 환경을 제공한다. 노드 컴포넌트의 종류로는 아래와 같다.
- kubelet: 클러스터의 각 노드에서 실행되는 에이전트. kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리한다.
- kube-proxy: 클러스터의 각 노드에서 실행되는 네트워크 프록시로 쿠버네티스 서비스 개념의 구현부이다.
- 컨테이너 런타임: 컨테이너 실행을 담당하는 소프트웨어 (Docker, Containerd, CRI-O, K8s CRI...)
쿠버네티스를 왜 사용하나?
지금까지 쿠버네티스의 구성 요소에 대하여 소개를 하였다. 그러면 실제로 쿠버네티스가 제공하는 기능들은 어떤 것이 있을까? 쿠버네티스에서 제공하는 기능은 여러가지가 있지만 대표적으로는 다음과 같다.
- 서비스 디스커버리와 로드밸런싱: 여러 노드에 배포된 컨테이너끼리 쿠버네티스에서 제공해주는 DNS로 쉽게 통신이 가능하다.
- 스토리지 오케스트레이션: 컨테이너 애플리케이션에 여러 스토리지를 붙일 수 있다.
- 자동화된 롤아웃과 롤백: 쿠버네티스에 배포된 컨테이너의 원하는 상태를 서술하면 쿠버네티스가 자동으로 현재 상태를 원하는 상태로 맞추게 해준다.
- 자동화된 빈 패킹: 컨테이너에 필요한 리소스(CPU / RAM) 양과 노드에서 남아있는 리소스 양을 비교하여 최적의 노드에 컨테이너를 자동 배치시킨다.
- 자동화된 복구: 컨테이너 애플리케이션이 죽거나 이상이 있는 경우, 쿠버네티스에서 자동으로 재배포하여 복구시킨다.
- 시크릿과 구성 관리: 컨테이너 애플리케이션 설정을 쿠버네티스에 저장하여 배포 시점에 어떤 설정을 사용하여 배포할지 정할 수 있다.
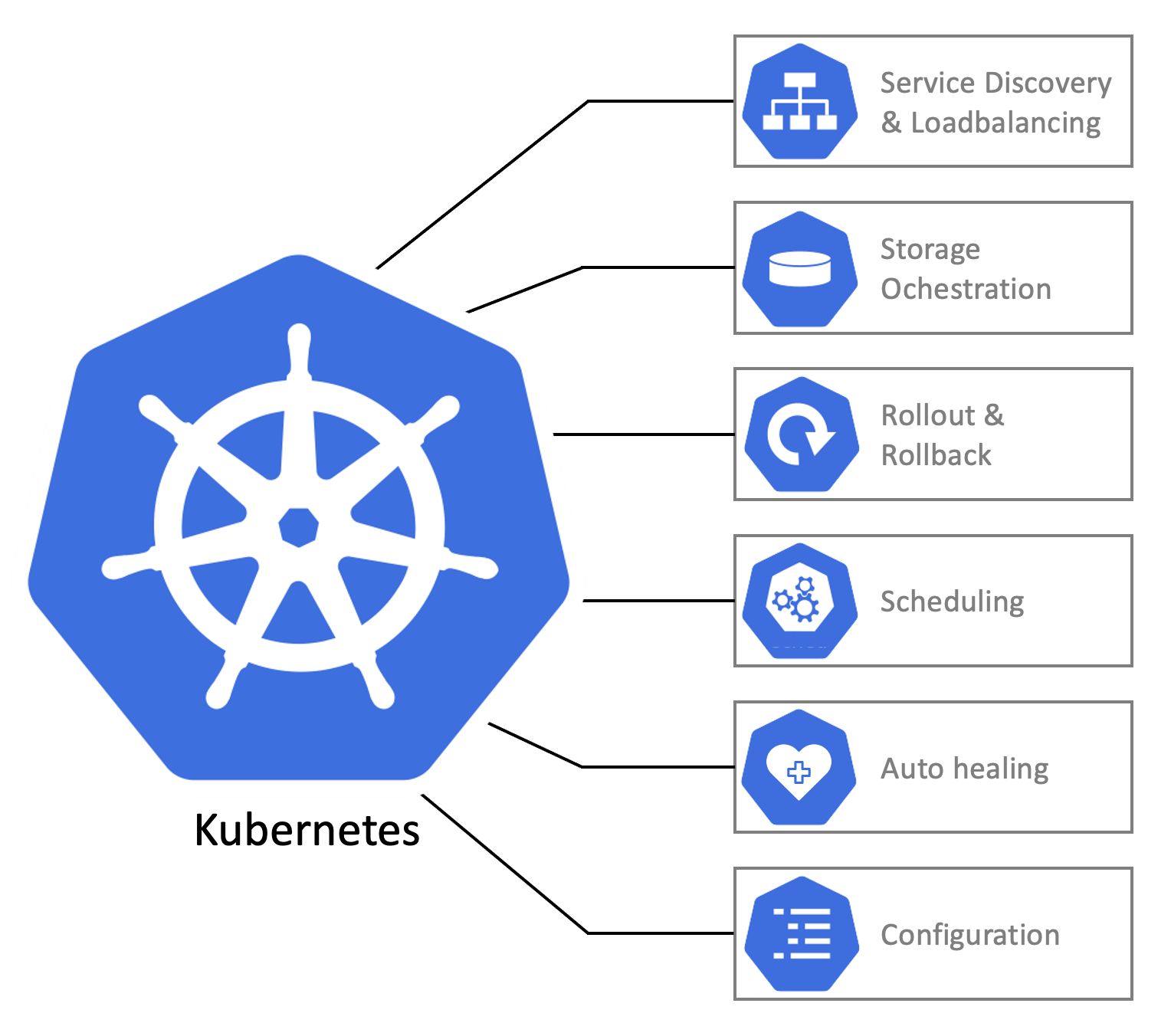
이런 기능들이 있다고 하는데, 쿠버네티스를 처음 접해보는 분들이라면 이런 기능이 왜 필요한지 감이 오지 않을 것이다. 이러한 기능이 왜 필요한지, 어떤 컴포넌트가 제공하는지 알아보자.
컨테이너 배포
우리가 컨테이너 애플리케이션을 배포하기 위해서는 이미지와 컨테이너 런타임이 있어야 한다. 대표적인 컨테이너 런타임으로는 도커가 있다. 만약 서버가 한 대 있다면 (또는 로컬에서) 컨테이너 애플리케이션을 배포하려면 명령어만 입력하면 컨테이너가 구동된다.
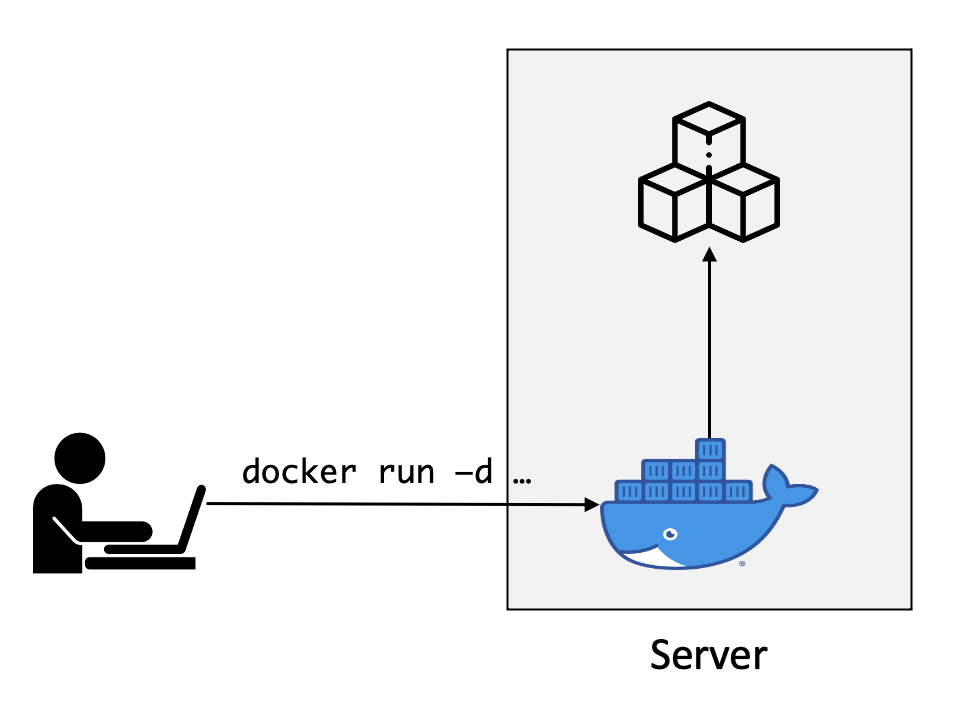
하지만 실 서비스를 운영할 때는 트래픽을 버티기 위해 여러 서버가 필요하며, 애플리케이션의 종류와 복제본 수도 많다. 이러한 환경일 경우에는 어떤 애플리케이션을 어떤 서버에 배포할지 결정해야 한다.
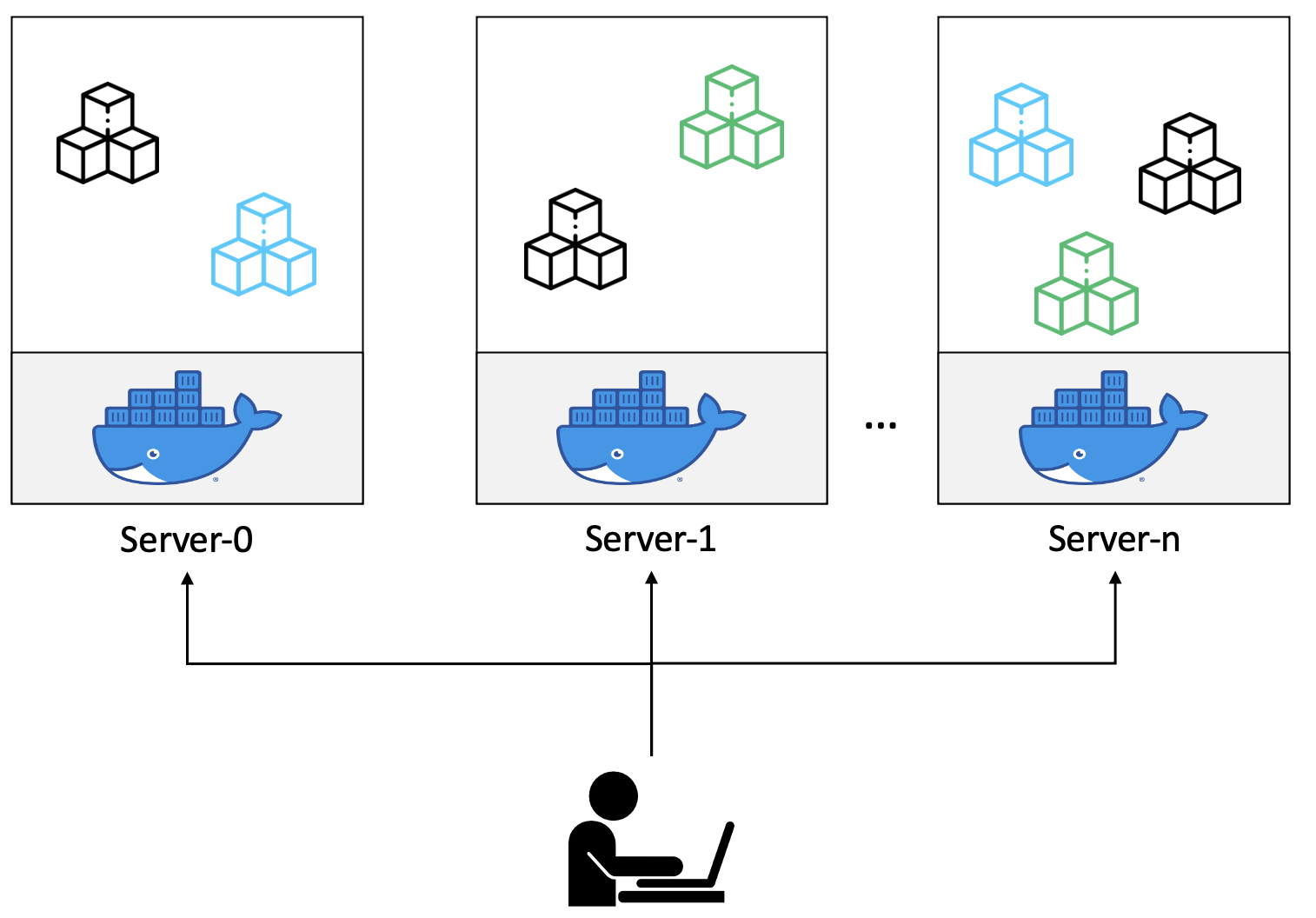
서버의 갯수가 많을수록, 애플리케이션 수가 많을수록 배포 환경을 관리하는 것은 상당한 부담이 있다. 먼저, 애플리케이션 스케줄링 전략을 세워야 하고 특정 서버의 장애 상황이 발생할 때 장애가 발생한 서버에 배포된 애플리케이션을 다른 서버로 이전하는 방식 등 장애 상황에 대해서도 대처 전략을 세워야 하기 때문이다.
쿠버네티스에서의 컨테이너 배포
쿠버네티스는 배포에 관련된 서버들은 하나의 클러스터로 묶어서 어떤 애플리케이션을 몇 개의 복제본으로 각각 어떤 노드(서버)에 배포할지 결정을 해주며, 컨테이너 애플리케이션 특정 노드에서 장애가 발생했을 때 장애를 자동으로 복구해주기도 한다. 개인적으로는 이 기능 때문에 쿠버네티스를 사용하는 것 같다.
먼저 쿠버네티스에서 애플리케이션을 어떻게 배포하는지 알아보자.

- 사용자는 쿠버네티스에서 제공하는 kubectl 이라는 CLI로 nginx를 쿠버네티스로 배포하는 명령어를 입력한다.
kube-apiserver는 사용자의 명령어를 받아etcd저장소에 배포할 파드의 정보를 저장한다. (파드는 쿠버네티스의 배포의 최소 단위로, 간단하게는 컨테이너 애플리케이션으로 생각하면 된다.)kube-scheduler는 주기적으로etcd를 확인하여 추가된 파드가 있는지 확인한 뒤 추가된 파드가 있다면 파드를 배치시킬 노드를 결정한다.- 노드를 결정했다면,
kube-scheduler는 해당 노드에 있는kubelet에게 컨테이너를 구동시키라는 명령을 한다. kubelet은 해당 노드에 있는 CRI(Container Runtime Interface)를 사용하여 컨테이너를 구동시킨다.
배포 과정에서는 kubectl로 kube-apiserver에게 요청만 하면 자동으로 컨테이너를 어느 노드에 배치할지 결정하고 배포까지 진행된다. 그렇다면 구동 중인 컨테이너가 장애가 발생할 경우에 쿠버네티스는 어떻게 동작할까?
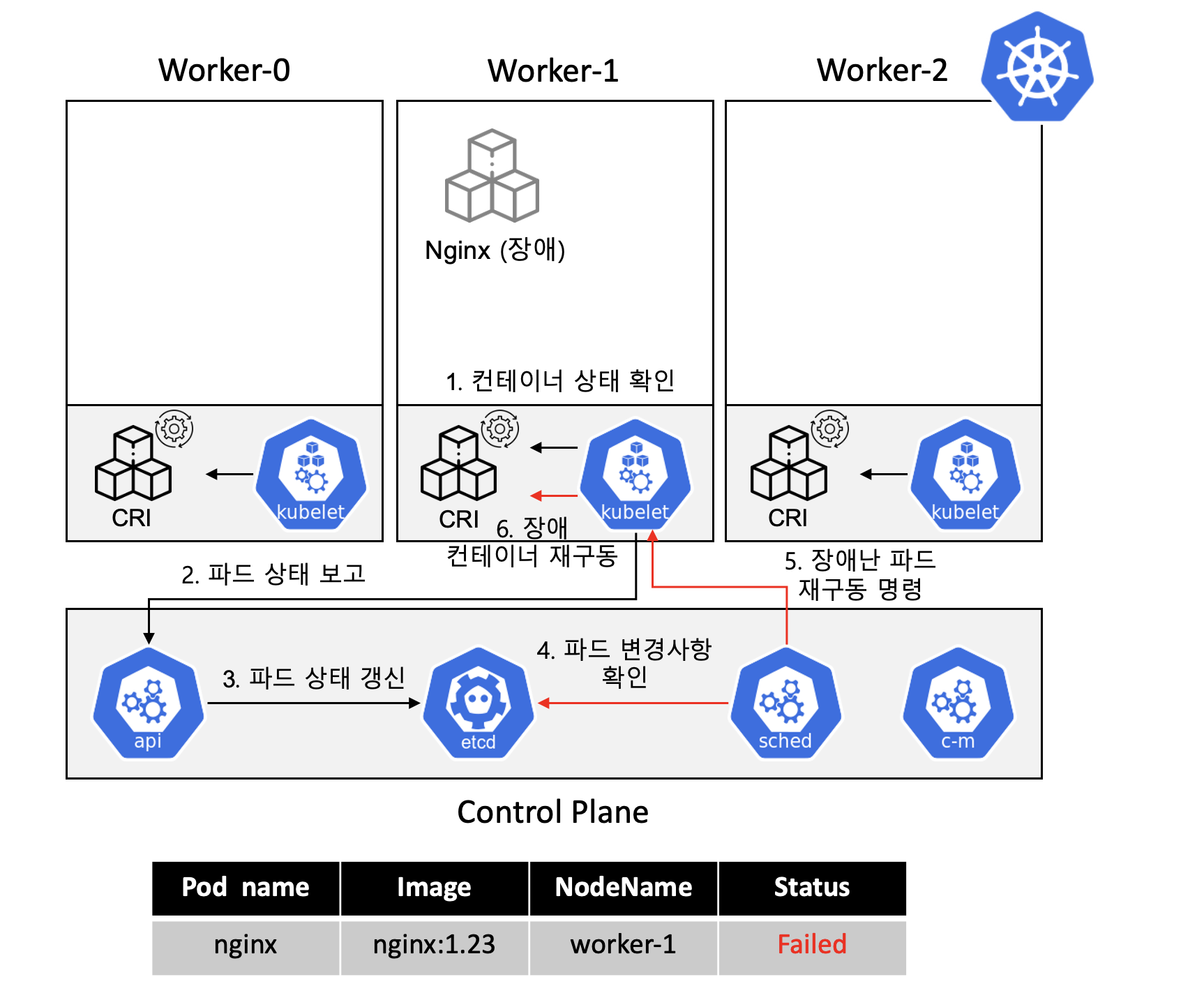
kubelet은 파드의 상태를 주기적으로 확인하여kube-apiserver에 보고한다.kube-apiserver는kubelet이 전달한 파드의 상태를etcd에 갱신한다.kube-scheduler는 주기적으로etcd에 저장된 파드의 상태를 확인한다.- 장애가 난 파드가 있다면 파드가 배치된 노드에 있는
kubelet에게 파드 재구동 명령을 한다. kubelet은 CRI를 사용하여 컨테이너를 재구동시켜 장애 복구를 진행한다.
쿠버네티스는 대략 이런 방식으로 자동화된 빈 패킹과 자동화된 복구 기능을 제공한다. 여기서 주목해야 할 점은 컨테이너 애플리케이션을 실제로 배포하고 관리하는 것은 etcd에 저장되어있는 정보를 기반으로 한다. 실제로 쿠버네티스는 쿠버네티스가 관리해야 할 것들의 원하는 상태(spec)를 etcd에 저장한다. 그리고 컨트롤 플레인에 있는 컴포넌트 (kube-scheduler, controller-manager 등)들이 etcd 에 저장된 spec이 실제 상태와 일치하도록 컨테이너 배포 명령 등의 작업을 수행한다. 이러한 방식이 선언적 구성 방식이다.
서비스 디스커버리와 로드밸런싱
클러스터 내 컨테이너끼리 통신을 해야 하는 경우에 대해 생각해보자. 일단 단순히 생각해봐도 어떤 애플리케이션이 어디에 있는지 알아야 통신이 가능할 것이다. 쿠버네티스에서는 클러스터 내에서 사용하는 가상의 네트워크가 있고, 하나의 파드에는 고유의 가상 IP가 부여된다. 하지만 컨테이너는 다른 컨테이너의 IP를 알기가 쉽지 않다. 그리고 파드의 복제본이 여러개 있을 수도 있고 새로운 버전으로 배포가 되면 파드의 IP가 변경된다. 쿠버네티스에서의 파드는 영구적이지 않은 일시적인 것으로 간주해야 한다.
그래서 쿠버네티스에서는 쿠버네티스 내 애플리케이션과 통신할 때 IP 기반이 아닌 DNS 기반으로 통신할 수 있도록 서비스 디스커버리와 로드밸런싱 기능을 제공해준다.
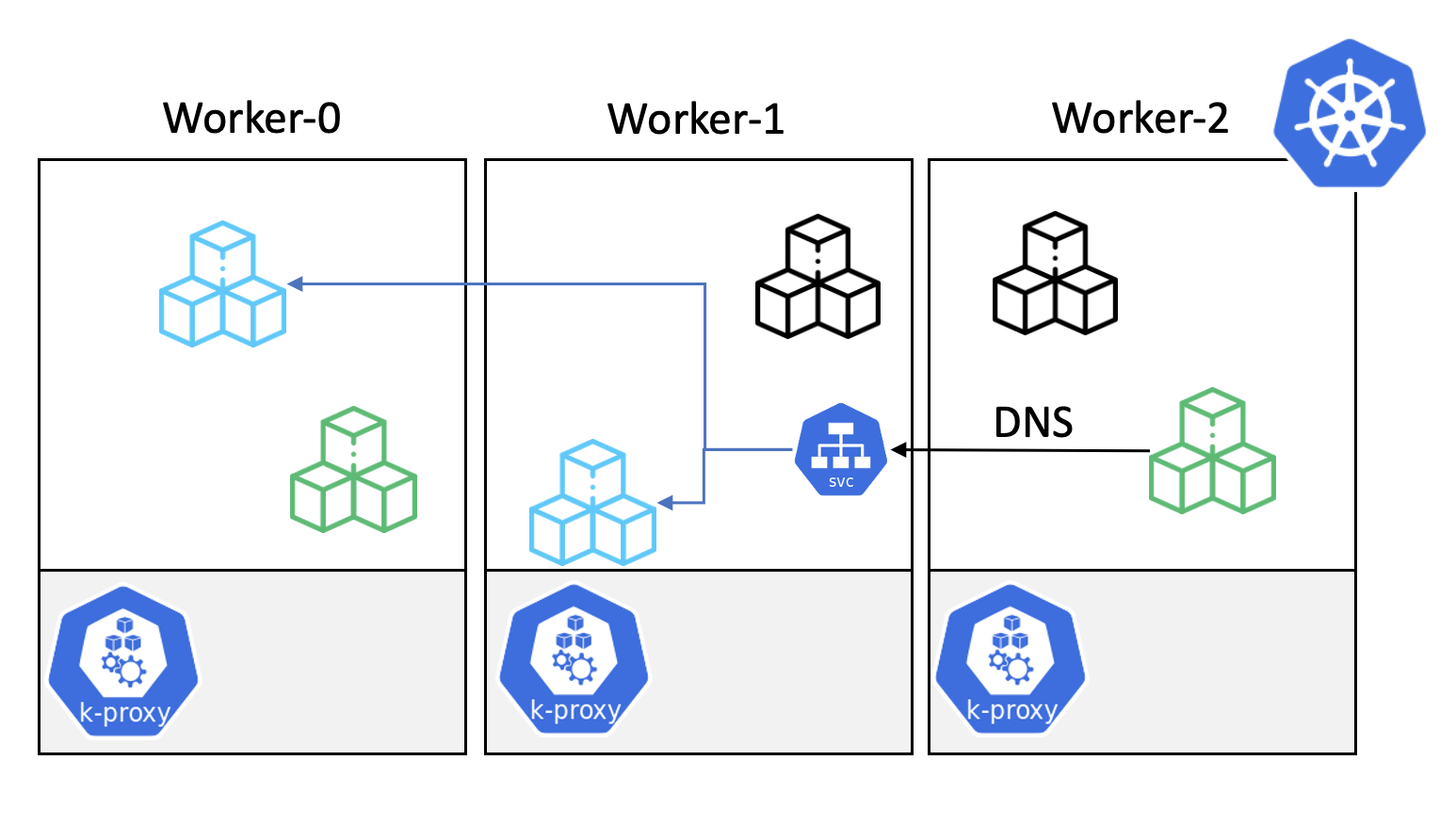
이 기능은 각 노드에 있는 kube-proxy를 통해 실제로 구현이 되며 쿠버네티스 Service에 대해 공부하면 자세히 알 수 있다.
자동화된 롤아웃과 롤백
쿠버네티스는 애플리케이션을 배포할 때마다 해당 배포 릴리즈 정보를 저장해둔다. 그리고 새로운 버전의 애플리케이션을 배포한다면 기본적으로 롤링배포를 통해 무중단 배포를 진행할 수 있다. 그리고, 배포 릴리즈 정보를 저장해두고 있기 때문에 저장된 릴리즈 정보를 바탕으로 특정 버전으로 롤백을 할 수 있다. 대신 롤백 기능을 사용하려면 이미지 버전을 태깅을 해야한다.
이러한 기능은 deployment, replicaset 등 쿠버네티스의 워크로드를 공부하면 알 수 있으며 이러한 기능은 kube-scheduler와 kube-controller-manager가 제공한다.
시크릿과 구성 관리
보통 배포 환경별로 애플리케이션 설정을 다르게 하여 애플리케이션을 배포할 것이다. 그러면 환경별로 달리할 애플리케이션 설정 정보들은 어디서 관리할까? 보통은 Github나 Vault 등의 저장소를 사용하여 애플리케이션 설정 정보들을 저장할 것이다. 그런데 쿠버네티스에서는 기본적으로 애플리케이션 설정 정보를 ConfigMap이나 Secret를 사용하여 저장할 수 있도록 기능을 내장화 하여 제공한다.
마무리
이번 장에서는 쿠버네티스에 대한 개략적인 소개를 알아보았다. 다음 장에서는 minikube나 kubeadm으로 쿠버네티스 클러스터를 설치하는 방법에 대하여 알아보자.
[2] 쿠버네티스 클러스터 설치
쿠버네티스 클러스터 설치 쿠버네티스 클러스터는 물리머신이나 가상머신에 모두 설치할 수 있다. 설치 방법은 여러가지가 있는데 minikube, kubeadm, k3s, microk8s 등이 있지만 minikube와 쿠버네티스 공
beer1.tistory.com
'DevOps > Kubernetes' 카테고리의 다른 글
| [7] 쿠버네티스 디플로이먼트 (2) | 2022.01.23 |
|---|---|
| [6] 쿠버네티스 파드 (1) | 2022.01.05 |
| [5] 쿠버네티스 오브젝트 (2) (0) | 2022.01.02 |
| [4] 쿠버네티스 오브젝트 (1) (2) | 2021.11.24 |
| [3] 쿠버네티스 고가용성 클러스터 설치 (1) | 2021.11.20 |




댓글