Kubernetes Scheduling
쿠버네티스에서 스케줄링은 파드를 실행할 쿠버네티스 클러스터에 있는 적절한 노드를 찾는 과정을 말한다. 기본적으로 쿠버네티스에서 스케줄링은 컨트롤 플레인에 있는 kube-scheduler라는 컴포넌트가 그 기능을 담당한다. 물론 쿠버네티스의 스케줄링 메커니즘을 잘 이해한다면 자신만의 커스텀 스케줄러를 구현하는 것도 가능하다.
kube-scheduler
kube-scheduler는 쿠버네티스의 컨트롤 플레인의 구성요소로, 쿠버네티스의 기본 스케줄러이다 kube-scheduler는 새로 생성되었지만 아직 노드에 스케줄링되지 않은 파드를 실행하기 위해 최적의 노드를 선택한다.
kube-scheduler에서 파드를 스케줄링을 할 때는 기본적으로 총 12단계를 거치게 된다. 그 중, 파드를 실행시킬 최적의 노드를 선택할 때는 각각 Filtering과 Scoring 단계에서 이루어진다.
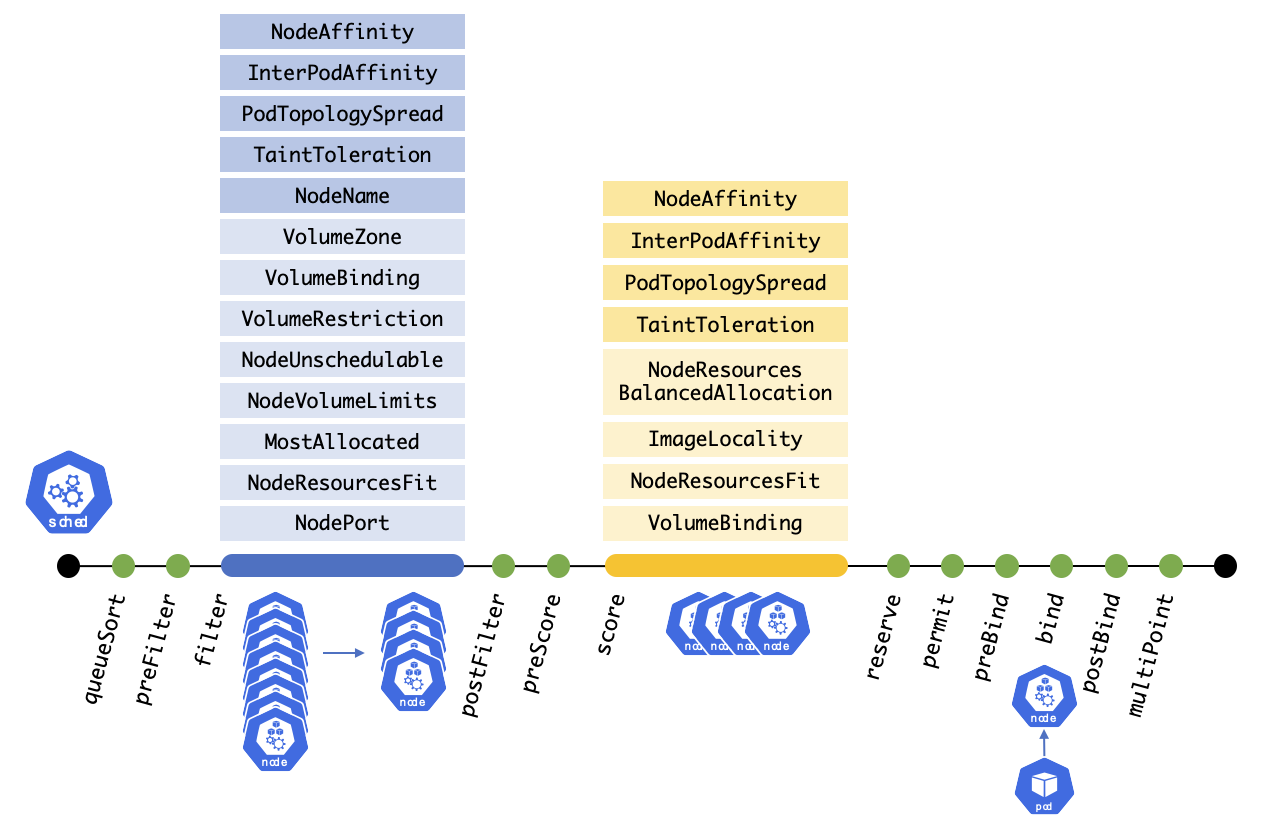
Filtering
Filtering 단계에서는 파드를 스케줄링 할 수 있는 노드 집합을 찾는다.
Filter 단계에서 기본적으로 활성화된 플러그인은 NodeAffinity 부터 NodePort 까지 총 13단계가 있으며, 운영자가 직접 제어할 수 있는 부분은 NodeAffinity 부터 NodeUnschedulable까지 총 6개 단계가 있다고 본다. 나머지 7개 단계에서는 노드의 실질적인 상태를 확인하여 파드를 스케줄링 할 수 있는지 확인을 한다고 보면 된다. 예를 들어 NodeResourcesFit 플러그인에서는 파드에서 지정한 resource requests를 수용할 수 있는 가용 리소스가 있는 노드가 있는지 확인한다.
이러한 단계가 끝나면 파드를 스케줄링 할 수 있는 노드집합이 결정되며, 노드 집합이 없다면 스케줄링을 할 수 없다.
Scoring
Filtering 단계가 끝난 후 파드를 스케줄링 할 수 있는 노드집합이 결정되고, 이 노드집합이 비어있지 않다면 해당 노드집합 중 파드를 실행시킬 최적의 노드를 찾기 위해 순위를 매긴다.
마찬가지로 Scoring 단계에서 기본적으로 활성화된 플러그인은 NodeAffinity 부터 VolumeBinding 까지 총 8단계가 있으며, 운영자가 직접 제어할 수 있는 부분은 NodeAffinity 부터 TaintToleration까지 4 단계이며 나머지 4개 단계에서는 노드의 실질적인 상태를 확인하여 파드를 스케줄링할 노드의 우선순위를 정한다.
이러한 단계가 끝나면 파드를 스케줄링 할 수 있는 노드가 결정된다.
스케줄링 제어 방식
앞서 말한대로 Filtering과 Scoring 단계 중에서 운영자가 제어할 수 있는 부분은 공통적으로 다음과 같다.
| 플러그인 | 내용 | Filtering | Scoring |
|---|---|---|---|
| NodeAffinity | NodeSelector와 NodeAffinity에 대한 스케줄링을 구현한다. | O | O |
| InterPodAffinity | InterPod Affinity / AntiAffinity에 대한 스케줄링을 구현한다. | O | O |
| PodTopologySpread | PodTopologySpread에 대한 스케줄링을 구현한다. | O | O |
| TaintToleration | Taint와 Toleration에 대한 스케줄링을 구현한다. | O | O |
| NodeName | Pod 스펙에 명시되어있는 nodeName을 확인한다. |
O | X |
| NodeUnschedulable | Node 스펙 중 unschedulable이 true로 설정되어있는 노드를 필터링한다. |
O | X |
우리는 이 6가지 방식에서 언급된 방식으로 파드를 특정 노드에 스케줄링 할지 결정할 수 있다. 이 각각에 대해서 하나씩 파악해보자.
NodeName

nodeName 방식은 가장 직관적이고 쉬운 방식으로 파드를 특정 노드에 바로 배치하는 방식을 말한다. Scheduler에서는 NodeName 플러그인에서 필터링 기능을 구현한다. nodeName은 파드 스펙의 필드(.spec.nodeName)이고, 파드 생성 시점에서 이 값이 비어있다면 스케줄러가 Filtering, Scoring을 거쳐서 나온 최적의 노드 이름으로 할당시켜준다. 하지만 nodeName 값이 지정되어있다면, 스케줄링을 하지 않고 해당 이름의 노드로 파드를 실행시킨다.
파드에 nodeName 을 지정하는 방법은 파드의 spec.nodeName을 지정한 후 적용하면 된다.
nodename-test.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: nodename-test
name: nodename-test
spec:
containers:
- image: nginx
name: nodename-test
nodeName: k8s-wn1$ kubectl apply -f nodename-test.yaml
파드를 생성한 후 -o wide 옵션으로 파드가 실행되는 노드를 확인해보면 k8s-wn1에 떠있는 것을 확인할 수 있다.

nodeName 필드를 사용하여 실제로 서비스하는 파드를 스케줄링 하는 것은 적절하지 않으며, 특정 상황에서만 사용되는 스케줄링 방식이다. 파드를 하나의 특정 노드에만 띄워야만 한다는건 쿠버네티스를 굳이 사용할 필요가 없다는 말과 비슷하다.
제약사항
nodeName을 사용하여 노드를 선택할 때에는 몇 가지 제약사항이 있다.
nodeName과 일치하는 노드가 없다면 파드는 실행되지 않는다. 경우에 따라 파드를 자동으로 삭제시킨다.nodeName과 일치하는 노드에 파드에 정의한 resource.requests 만큼의 리소스가 없다면 파드가 실패하고 OutOfMemory 또는 OutOfCpu와 같은 실패 사유가 뜬다.
nodeSelector
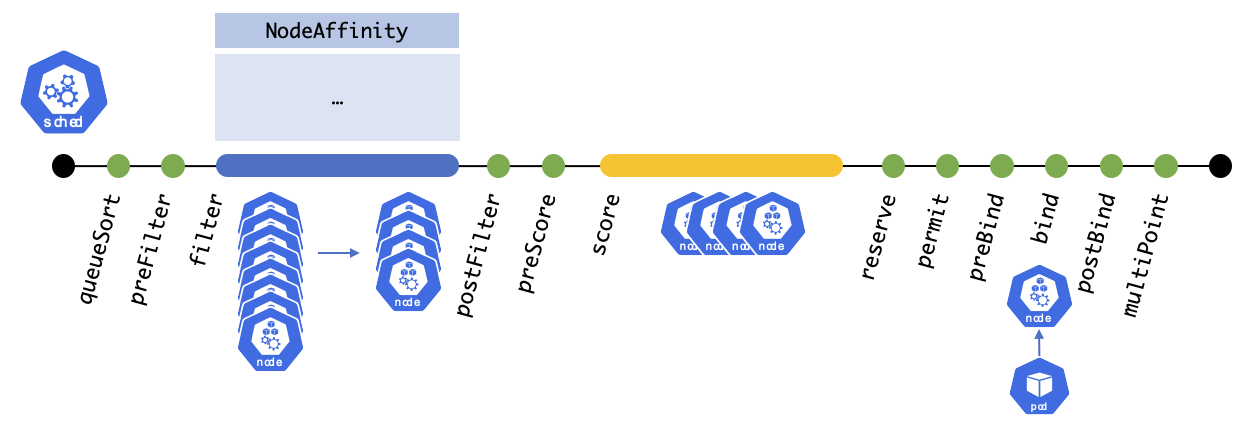
nodeName을 제외하면 nodeSelector 방식이 파드를 특정 노드로 스케줄링하도록 하는 가장 간단한 방법이다. Scheduler에서는 NodeAffinity 플러그인에서 nodeSelector에 대한 필터링 기능을 구현한다. (오타 X) 파드를 특정 노드에서 스케줄링하려고 한다면, 먼저 스케줄링 되어야하는 노드 집합을 결정해야 한다. 그 노드 집합에서 각 노드마다 특정 레이블을 심어주고 파드 스펙에 nodeSelector 필드를 추가한 후 파드를 생성하면 된다.
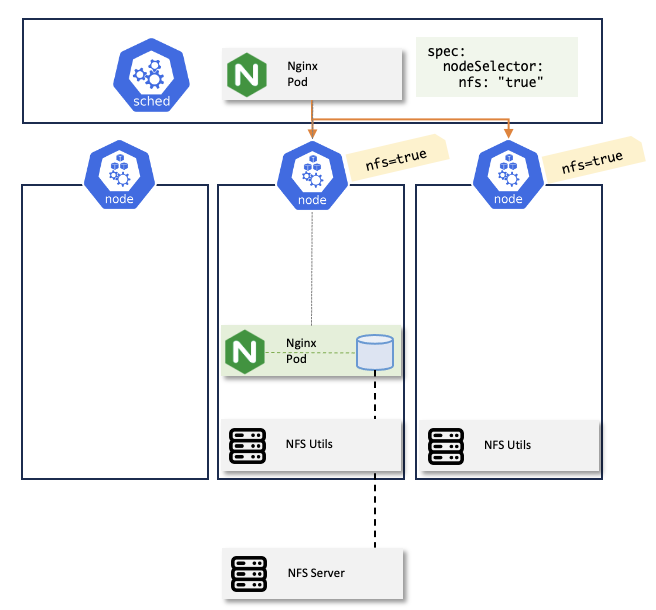
NodeSelector의 예제로, NodeSelector를 사용하여 NFS 볼륨을 사용하는 파드를 스케줄링 하는 방법에 대해 알아보자.
Node 설정
NFS 볼륨을 사용해야 하는 파드가 있다고 하자. NFS로 볼륨을 마운트 하려면 노드에 nfs-utils가 깔려있어야 한다.
# Centos
$ yum install nfs-utils
# Ubuntu
$ apt-get install nfs-common
특정 몇 개의 노드에 nfs-utils를 깔고, 그 노드에 nfs=true 라는 레이블을 추가하면 일단 파드를 스케줄링할 노드를 구성하는 작업은 끝이다. 고가용성을 위해 적어도 노드 2~3개정도는 같은 레이블을 가지고 있는게 좋다. 일단 지금은 개인환경에 워커노드가 두대 뿐이라서 노드 한 대에만 레이블을 설정하였다.
$ kubectl label no k8s-wn1 nfs=trueNFS 서버 설정
그 다음 실제로 NFS 서버가 필요한데, NFS서버가 없다면 직접 서버를 구축해야 한다. Ubuntu에서 NFS 서버를 설치하는 방법은 다음과 같다.
$ sudo apt update
$ sudo apt install nfs-kernel-server
그 다음 NFS볼륨을 마운트하는 경로를 추가하자. 경로는 아무거나 상관 없다.
$ mkdir -p /home/beer1/nfs
그 다음 NFS를 마운트하려는 클라이언트의 IP를 허용하는 룰을 추가해야 하는데 /etc/exports에서 설정할 수 있다. 여기서 허용할 IP는 nfs-utils를 설치한 쿠버네티스 워커노드의 IP이다.
/home/beer1/nfs 192.168.35.2(rw,sync,no_subtree_check)
NFS 서버와 노드 설정을 마쳤다면, 실제로 NFS 볼륨을 사용하는 파드를 생성해보자.
Pod 설정
일단 NFS를 사용하여 PV, PVC를 생성하자.
apiVersion: v1
kind: PersistentVolume
metadata:
name: nginx-nfs
spec:
capacity:
storage: 1Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.35.167
path: "/home/beer1/nfs/nginx"
mountOptions:
- nfsvers=4.2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
volumeName: nginx-nfs
그 다음 NFS 볼륨을 사용하는 파드를 구성해보자. 파드의 volumes 설정과 컨테이너 volumeMounts 설정으로 nginx 컨테이너에서 nfs 볼륨을 마운트하도록 구성하자. 그 다음, NFS 볼륨을 마운트할 수 있도록 nfs-utils가 깔린 노드로 스케줄링되도록 NodeSelector를 구성해야 한다. 이 때는 .spec.nodeSelector 필드를 추가해주면 된다. nfs-utils가 깔린 노드에 nfs=true 레이블을 등록했기 때문에 여기서도 .sepc.nodeSelector 부분에 nfs: true 를 추가해주면 된다.
apiVersion: v1
kind: Pod
metadata:
name: nodeselector-test
spec:
nodeSelector:
nfs: "true"
containers:
- name: nginx
image: nginx
volumeMounts:
- name: contents
mountPath: /contents
volumes:
- name: contents
persistentVolumeClaim:
claimName: nginx-nfs-pvc
실제로 적용 후 파드를 조회해보면 파드가 잘 뜨는 것을 확인할 수 있다.

nfs-utils가 설치되지 않은 노드로 스케줄링된다면?
만약 NFS 볼륨을 마운트하는 파드가 nfs-utils가 설치되지 않은 노드로 스케줄링된다면 어떻게 될까? 해보면 알겠지만 NFS 볼륨을 마운트할 수 있는 도구가 없기 때문에 파드가 정상적으로 뜨지 않을 것이다.
.spec.nodeSelector 부분을 주석처리하고 .spec.nodeName으로 nfs-utils가 설치되지 않은 노드로 설정하여 강제로 스케줄링해보자.
apiVersion: v1
kind: Pod
metadata:
name: nodeselector-test
spec:
nodeName: k8s-wn2
#nodeSelector:
# nfs: "true"
containers:
- name: nginx
image: nginx
volumeMounts:
- name: contents
mountPath: /contents
volumes:
- name: contents
persistentVolumeClaim:
claimName: nginx-nfs-pv
파드를 조회해보면 ContainerCreating 상태로 계속 머물게 되는데, describe 명령어로 이벤트를 확인해보면 마운트가 실패했다는 이벤트를 볼 수 있다.

마무리
이번 글에서는 kube-scheduler와 Flitering, Scoring에 대해 간단히 소개를 했고, 운영자 입장에서 파드를 스케줄링 하는 기법 중 NodeName, NodeSelector에 대해 알아보았다. 다음 글에서는 이번 글에서 언급한 기법 외의 다른 기법에 대해서도 정리를 할 계획이다.
2024.05.02 - [DevOps/Kubernetes] - Kubernetes Scheduling - Node Affinity
Kubernetes Scheduling - Node Affinity
Affinity를 사용하여 파드를 스케줄링할 노드를 찾을 때의 제약조건을 정의할 수 있다. Affinity를 사용하면 이전 시간에 언급한 nodeSelector보다 더 풍부한 방식으로 파드를 실행시키는 노드의 조건을
beer1.tistory.com
참고자료
https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/
Kubernetes Scheduler
In Kubernetes, scheduling refers to making sure that Pods are matched to Nodes so that Kubelet can run them. Scheduling overview A scheduler watches for newly created Pods that have no Node assigned. For every Pod that the scheduler discovers, the schedule
kubernetes.io
https://kubernetes.io/docs/tasks/configure-pod-container/assign-pods-nodes/
Assign Pods to Nodes
This page shows how to assign a Kubernetes Pod to a particular node in a Kubernetes cluster. Before you begin You need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. It is recommended to
kubernetes.io
https://kubernetes.io/docs/reference/scheduling/config/#profiles
Scheduler Configuration
FEATURE STATE: Kubernetes v1.25 [stable] You can customize the behavior of the kube-scheduler by writing a configuration file and passing its path as a command line argument. A scheduling Profile allows you to configure the different stages of scheduling i
kubernetes.io
'DevOps > Kubernetes' 카테고리의 다른 글
| Kubernetes HPA (파드 오토스케일링) [1] - 기초 (0) | 2025.01.05 |
|---|---|
| Kubernetes Scheduling - Node Affinity (0) | 2024.05.02 |
| [1] 쿠버네티스 확장 - kubectl plugin (0) | 2023.10.29 |
| Helm Chart Repository 만들기 (2) - Harbor OCI registry (0) | 2023.10.12 |
| Helm Chart Repository 만들기 (1) - Github (0) | 2023.10.09 |




댓글