이번 시간에는 Prometheus에서 저장하는 데이터 구조에 대해 알아보고, PromQL에 대해 간략하게 알아보는 시간을 가져보자.
Data model
Prometheus는 기본적으로 모든 데이터를 시계열 데이터로 저장한다. Prometheus가 저장하는 메트릭의 데이터 구조를 보면 크게 4가지로 나뉘게 된다.
- metric name: 메트릭 종류
- metric labels: 메트릭 종류에 대한 차원 데이터
- timestamp: 메트릭을 수집한 시점
- value: 수집된 메트릭 값

metric name
metric name은 측정되는 시스템의 일반적인 가능을 지정한다. 위의 그림에서 container_memory_rss 라는 것이 metric name인데, 해당 메트릭은 컨테이너의 실제 사용 메모리 바이트가 얼마인지를 타나낸다고 보면 된다.
metric label
metric label은 해당 메트릭을 여러 차원으로 나눌 수 있도록 한다. container_memory_rss 메트릭의 label을 보면 instance, namespace, pod, container 등이 있는데 크게 4가지만 본다면 각각 워커노드, 쿠버네티스 네임스페이스, 파드 이름, 컨테이너 이름 으로 나타낼 수 있다. PromQL으로 쿼리를 하는 경우, 이러한 레이블을 기반으로 필터링과 집계 등을 활용할 수 있다.
Notation
메트릭 이름과 레이블 집합이 주어지면 시계열 데이터는 다음 표기법을 사용한다.
<metric name>{<label name1>=<label value1>, <label name2>=<label value2>, ...}
예를 들어, k8s-wn2 워커노드의 bookinfo 네임스페이스에 있는 container_memory_rss 를 확인하고 싶다면 다음과 같이 나타내면 된다.
container_memory_rss{instance="k8s-wn2", namespace="bookinfo"}Metric types
Prometheus는 저장하는 메트릭마다 고유한 타입을 가지고 있다. Prometheus에서 제공하는 메트릭 타입은 다음과 같다.
Counter
Counter는 값이 재시작 시에만 증가하거나 0으로 재설정되는 단순 증가하는 누적 메트릭이다. 예를 들어 서버 누적 요청량이나 에러 양 같은 데이터를 Counter로 사용할 수 있다.
Gauge
Gauge는 증가하거나 감소할 수 있는 상태값을 수치로 나타내는 메트릭이다. 예를 들어 메모리 사용량이라 쓰레드 사용량 등을 Gauge로 사용할 수 있다.
Histogram
Histogram은 관측값을 샘플링하여 구성 가능한 버킷에서 카운트하고 관찰된 모든 값의 합계를 제공한다. <basename> 이라는 기본 메트릭 이름을 가진 히스토그램은 스크래핑 중에 여러 타임시리즈를 노출한다.
- 관측 버킷에 대한 누적 카운터는
<basename>_bucket{le="<upper inclusive bound>"}로 노출된다.- le는 lettle or equal 으로,
coredns_dns_request_duration_seconds_bucket{..., le="0.001}은 le를 제외한 나머지 레이블을 만족하는 coredns 요청 중 응답시간이 0.001 이하인 요청 갯수를 의미한다. - le의 가장 큰 값은 +Inf이며, +Inf인 경우는 총 요청 갯수와 같다.
- le는 lettle or equal 으로,
- 관측된 모든 값에 대한 총 합은
<basename>_sum으로 노출된다. - 관측된 이벤트에 대한 카운트는
<basename>_count로 노출된다.
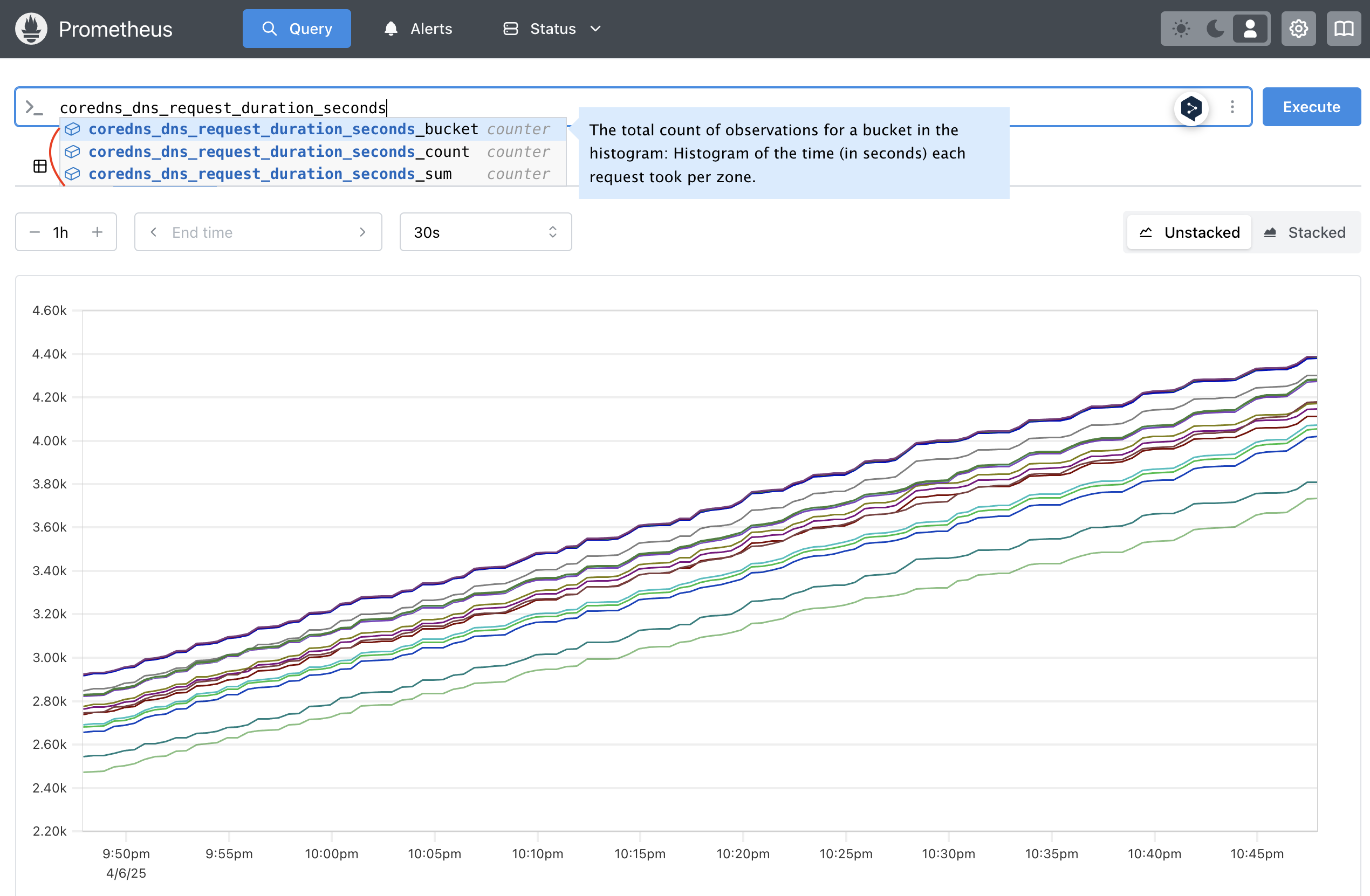

Histogram 메트릭은 보통 histogram_quantile() 함수와 자주 사용되는데, 이 함수를 사용하면 히스토그램의 분위수를 대략으로 구할 수 있다.
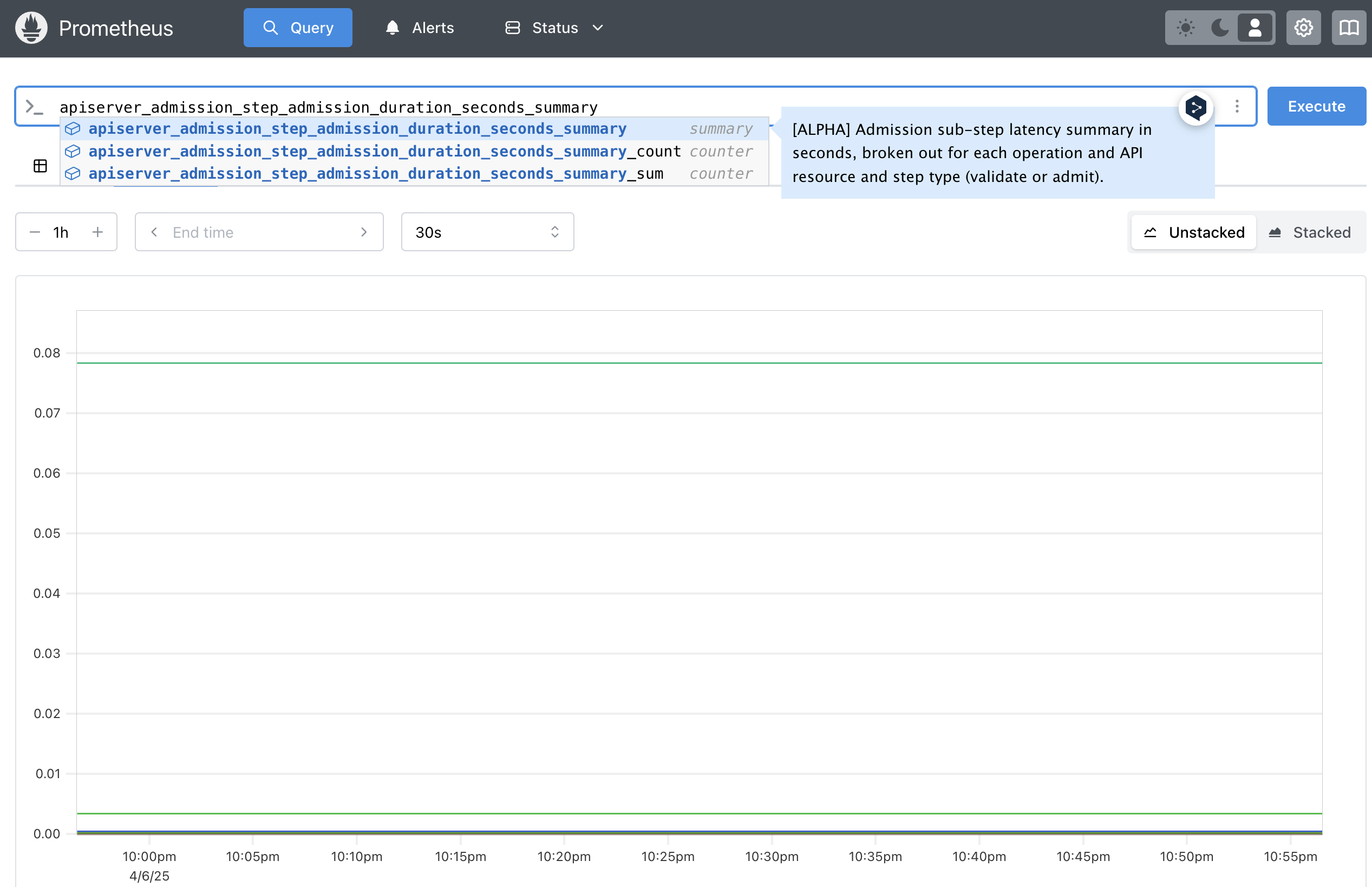
Summary
histogram과 마찬가지로 Sumamry는 관측값을 샘플링한다. 또한 총 관측 횟수와 모든 관측 값의 합계를 제공하지만 슬라이딩 시간 창에 대해 구성 가능한 분위수를 계산한다.
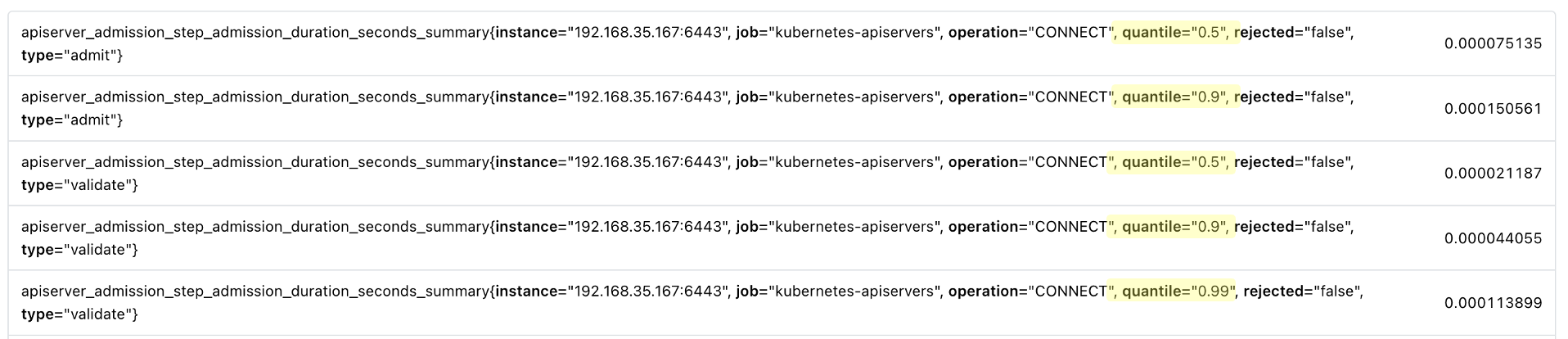
- 관측된 이벤트의 특정 분위수를 스트리밍하는 메트릭이 있다.
<bsename>{quentile="<N>"}으로 노출된다. - 관측된 모든 값에 대한 총 합은
<basename>_sum으로 노출된다. - 관측된 이벤트에 대한 카운트는
<basenmame>_count로 노출된다. - 전반적으로 histogram과 닮아있지만 차이가 있다면 histogram은 특정 값 사이 구간의 갯수를 저장하는 한편, Summary는 특정 분위수에 대한 값을 저장한다.
PromQL
Prometheus의 메트릭을 활용하기 위해서는 PromQL을 사용할 줄 알아야 한다. 보통 Prometheus의 메트릭을 Grafana에서 시각화하기 위해 PromQL을 사용하거나 Alert rule을 정의하기 위해 PromQL을 사용하는 등 모니터링 시스템을 전반적으로 구축할 때 PromQL을 자주 사용하게 된다.
표현 언어 데이터 타입
PromQL에서 표현식에는 크게 4가지 종류의 타입으로 나타낼 수 있다.
- Instance vector : 각 시계열에 대해 단일 샘플을 포함하는 시계열 세트로, 모두 동일한 타임스탬프를 공유한다.
- Range vector : 각 시계열에 대 시간 경과에 따른 데이터 포인트 범위를 포함하는 시계열 집합이다.
- Scalar : 실수값
- String : 문자열 값으로 현재는 사용하지 않는다.
리터럴
PromQL에서 문자열과 숫자의 표현 방식에 대해 알아보자.
문자열 리터럴
PromQL에서 문자열은 다음과 같이 표현할 수 있다.
- 쌍따옴표 (
"") 로 감싸는 방법 - 따옴표 (
'') 로 감싸는 방법, (\n,\\,\t가 이스케이프 되지 않는다.) - 백쿼터 (```
) 로 감싸는 방법, (\n,',",\t` 가 이스케이프 된다.)
실수타입 리터럴
실수 타입은 다음과 같이 표현할 수 있다.
23
-2.43
3.4e-9 ## 3.4 * 10^9
1_000_000 ## 3자리씩 끊어서 표현
.123_456_789 ## 소숫점도 가능
0x8f ## 16진수
0x_53_AB_F3_82 ## 16진수 2자리씩 끊어서 가능
-Inf, Inf ## 무한대 표현
NaN기간 리터럴
기간은 다음과 같이 표현할 수 있다.
ms: millisecondss: secondsm: minutesh: hoursd: daysw: weeksy: years
물론 여러가지를 혼용해서 사용하는 것도 가능하다.
1h30m (== 90m == 5400s)Instant Vector
Instant vector selector를 사용하면 주어진 타임스탬프에서 시계열 집합과 각 시계열에 대한 단일 샘플을 선택할 수 있다. 가장 간단한 방식으로는 메트릭 이름으로만 쿼리할 수 있는데, 이렇게 하면 해당 메트릭 이름에 대한 가장 최근 시계열 샘플을 얻을 수 있다.
node_memory_Active_bytes- 해당 쿼리에서는 node_memory_Active_bytes 메트릭의 시계열 집합을 가져오고, 각 시계열에 대한 가장 최신의 단일 샘플을 가져온다.
- 특정 시간에 대한 단일 샘플만 추출하기 때문에 instant vector라고 한다.

Selector
PromQL은 Instant vector를 쿼리할 때 특정 레이블 조건을 만족하는 시계열 집합을 추출할 수 있도록 selector를 지원하고 있다.
apiserver_request_total{resource="pods"}- 해당 메트릭은 Kubernetes API Server 요청에 대한 메트릭이다.
- pod API에 대한 요청만을 쿼리하고 싶으면 이런 방식으로 하면 된다.
만약 레이블 값이 특정 값을 만족하지 않는 경우를 추출하고 싶다면 != 연산자를 사용하면 된다.
apiserver_request_total{resource!="pods"}여러 조건 선언 가능
레이블 조건은 두 가지 이상 선언이 가능하며 , 으로 구분한다.
apiserver_request_total{resource="pods", verb="GET"}정규식 가능
레이블 값이 특정 정규식 조건을 만족하는 경우를 추출하는 것도 가능하다. 특정 정규식 조건을 만족하는 경우에는 =~ 을, 만족하지 않는 경우에는 !~ 연산자를 사용하면 된다.
apiserver_request_total{resource="pods", verb=~"GET|LIST|WATCH"}- pod API 중 조회성 API만 추출할 때 이렇게 사용하면 된다.
Range Vector
Range vector는 Instant vector와 비슷하지만 단일 샘플이 아닌 범위 샘플을 가진다는 점에 차이가 있다. Range vector는 Instant vector의 쿼리에서 [] 으로 시간 범위를 지정하면 된다.
node_memory_Active_bytes[1m]- node_memory_Active_bytes 메트릭의 현재부터 1분전 데이터까지의 범위를 쿼리한다.
- 쿼리 값을 보면
숫자 @ 숫자로 되어있는데, 각각 앞의 숫자는 timestamp 이고, 뒤의 숫자는 메트릭 값이다. - 여기서 각 항목마다 4개의 값이 추출되는데, 범위의 갯수는
scrape_interval과 관련되어 있다. 현재 기준으로scrape_interval이 15초로 잡혀있기 떄문에 1분 / 15초 인 4개가 추출된다.

Range vector도 Instant vector와 마찬가지로 selector를 사용할 수 있다.
apiserver_request_total{resource="pods", verb="GET"}[1m]offset modifier
offset modifier는 쿼리에서 instance vector와 range vector의 오프셋을 변경하도록 해준다. 예를 들어, 현재 시간 기준으로 15분 전의 node_memory_Active_bytes 값을 보고싶다면 다음과 같이 쿼리하면 된다.
node_memory_Active_bytes offset 15m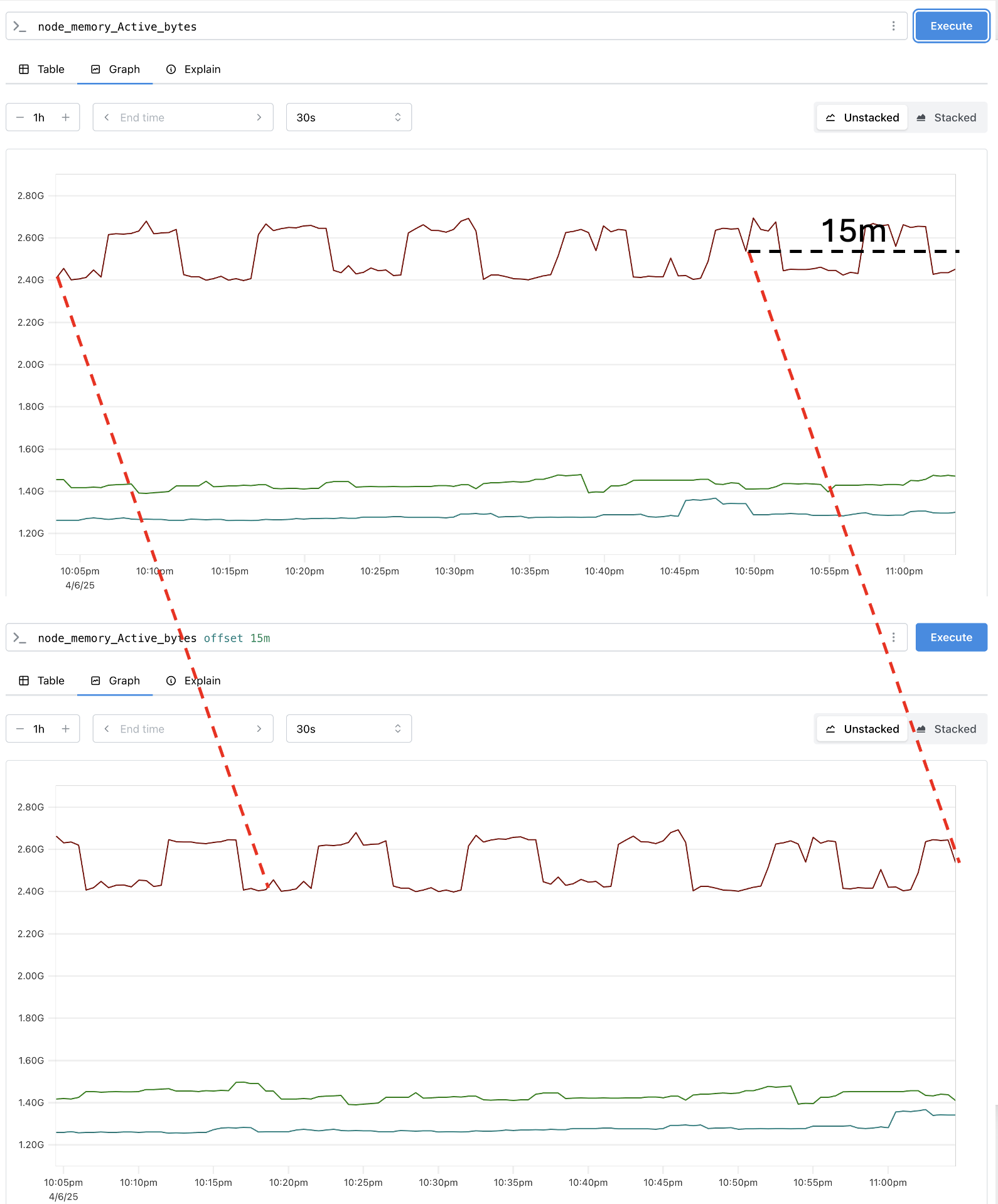
offset 은 항상 메트릭 이름이나 selector 뒤에 와야 한다.
sum(node_memory_Active_bytes{instance="192.168.35.167:9100"} offset 15m) ## (O)
sum(node_memory_Active_bytes{instance="192.168.35.167:9100"}}) offset 15m ## (X)
만약 과거 타임스탬프를 기준으로 쿼리를 할 경우, offset을 음수로 두면 지정한 타임스탬프 이후의 시간으로 비교할 수 있다.
node_memory_Active_bytes -15m@ modifier
@ modifier는 쿼리에서 instance vector와 range vector의 평가 시간을 변경하도록 해준다. @ modifier에 제공된 시간은 유닉스 타임스탬프이다.
예를 들어 2025년 4월 6일 22시 30분의 node_memory_Active_bytes을 확인하고 싶다면 다음과 같이 쿼리하면 된다.
node_memory_Active_bytes @ 1743946200
offset modifier와 마찬가지로 @ modifier도 메트릭 이름이나 selector 뒤에 와야 한다.
sum(node_memory_Active_bytes{instance="192.168.35.167:9100"} @ 1743946200) ## (O)
sum(node_memory_Active_bytes{instance="192.168.35.167:9100"}) @ 1743946200 ## (X)'DevOps > Monitoring' 카테고리의 다른 글
| Prometheus 소개 및 쿠버네티스에 설치 (0) | 2025.03.20 |
|---|

댓글