Garbage Collector
Garbage Collection는 JVM에서 자바의 메모리를 관리하는 방법으로, 애플리케이션에서 더 이상 참조되지 않는 객체의 메모리를 회수하는 자동 메모리 관리 방식이다.
자바 애플리케이션을 개발할 때 new 연산자를 사용하여 객체를 생성하게 된다.
void newPerson() {
Person p = new Person(20, "beer1");
...
}
이 때 p라는 객체는 Heap이라는 메모리 영역에 저장된다.

main() 메서드에서 해당 메서드를 호출한다면, Stack 영역에서는 main StackFrame 위에 newPerson() 에 해당하는 StackFrame이 생성되고, p라는 변수를 할당했으니 newPerson() StackFrame에 p 객체 주소값을 가지는 변수가 할당된다. 그리고 실제로 p 객체는 Heap 영역에서 할당된다.
그런데 여기서 newPerson() 메서드 호출이 종료되면 어떻게 될까? newPerson() 호출이 종료되면 newPerson() 에 해당하는 StackFrame이 제거되는데, p 객체의 실제 내용을 참조하는 변수가 사라졌기 때문에 p 객체의 실제 내용을 참조하는 것이 불가능해진다.
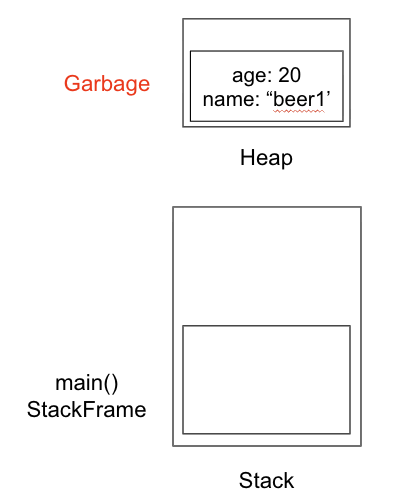
바로 이러한 객체를 가비지(Garbage) 라고 한다. 그리고 이러한 가비지를 주기적으로 제거하는 역할을 하는 것이 가비지 콜렉터 (Garbage Collector; GC) 라고 한다.
Root Space
조금 더 정확히는, Garbage는 Root space에서 참조가 불가능한 메모리 영역으로 간주되며, Root space의 종류로는 여러가지가 있다.
- Stack의 로컬 변수
- Method Area의 Static 변수
- Native Method Stack의 JNI
- 활성 쓰레드
GC 종류
JVM에서 제공하는 GC의 종류는 다양하며, GC를 애플리케이션 특성에 맞게 사용하는 것이 중요하다. 대표적인 GC의 종류로는 다음과 같다.
- Serial: 단일 쓰레드에서 순차적으로 GC를 수행하는 가장 기본적인 방식이다.
- Parallel: 다중 쓰레드를 사용하여 GC를 수행, Serial에서 다중 쓰레드 방식으로 변형한 방식이다.
- G1: 힙을 작은 영역으로 분할하여 GC를 수행하는 방식이며, STW를 예측 가능한 범위에서 최소화하는 것을 목표로 한다.
- CMS: 애플리케이션 실행과 GC를 동시에 진행하여 STW를 최소화하는 방식이다.
- ZGC: 힙을 작은 영역으로 분할하여 GC를 수행하는 방식이며, 대용량 메모리에서 초저지연을 목표로 한다.
Serial GC
Serial GC는 가장 단순한 방식의 GC로 mark-sweep-compact 알고리즘을 사용하여 가비지를 처리한다.
먼저, Heap 영역을 Eden, Survivor(0, 1), Old 영역으로 나눈다. 그리고 처음 객체가 생성되면 JVM은 Eden 영역에 객체를 할당한다.

Young GC (Minor GC)
객체가 계속 생성되어 Eden 영역이 꽉 찬 경우 Young GC가 발생한다.

이 때 GC는 도달 가능한 객체를 Survivor 영역으로 복사하고, Eden을 비운다. 이러한 방식을 Copy 방식이라고 한다.

Young GC가 발생하면 객체의 메모리 위치가 변경되기 때문에 애플리케이션이 잠깐 일시정지된다. 메모리 영역 변경으로 인해 애플리케이션이 일시정지 되는 현상을 STW(Stop The World) 라고 한다. Copy로 인해 발생하는 STW는 정지시간이 짧다.
Young GC로 인해 메모리가 정리되고 시간이 흐른 후 다시 Eden 영역이 꽉차면 다시 Young GC가 발생하는데, 이 때는 Eden 및 채워진 Survivor 영역이 정리되는데, 접근 가능한 객체가 채워지지 않은 Survivor 영역으로 복사되고, 나머지는 비워진다.


Promotion
Young GC 중에서 Survivor 영역에서 접근 가능한 객체 중 일정 시간이 지난 객체는 Old 영역으로 승격하게 된다. 이를 Promotion 이라고 한다.


Old GC (Major GC)
대부분의 객체는 일시적으로 사용하는 객체이기 때문에 Young GC에서 소멸된다. 대표적으로는 웹 애플리케이션에서 API의 응답을 표현하거나 응답을 내리기 위해 연산을 위해 사용되는 객체가 있는데, 해당 객체는 응답이 나가고나면 쓰레드가 제거되기 때문에 Young GC에서 사라진다.
하지만 로컬 캐시와 같이 어느정도 시간을 유지하는 객체도 있다. 이러한 객체가 Old 영역으로 승격하게 되는데, 시간이 지난 후 Old 영역까지 꽉 찰 가능성도 있다. 이 때는 Old 영역을 정리하게 되는데 이를 Major GC라고 한다. Major GC는 Mark, Sweep, Compact 단계로 진행된다.
먼저 Mark 단계에서는 도달 가능한 객체를 마킹한다. 아래 그림에서는 Old 영역의 보라색으로 되어있는 공간이 마킹된 영역으로 보면 된다.
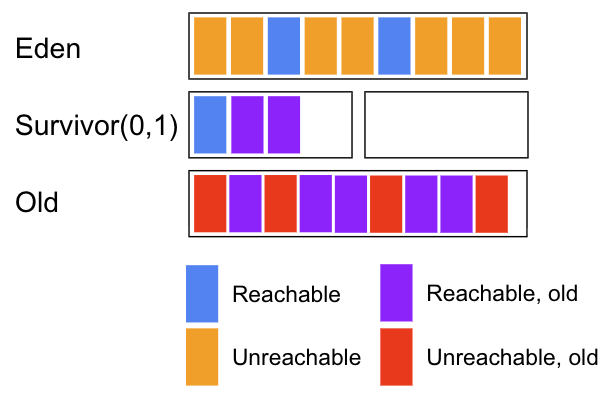
마킹이 끝나면 Sweep 단계를 진행하며, Sweep 단계에서는 마킹되지 않은 객체를 해제한다.

Sweep 단계가 끝나면 Compact 단계를 진행한다. Compact 단계에서는 살아있는 객체를 연속되게 재배치하는 작업을 진행한다.
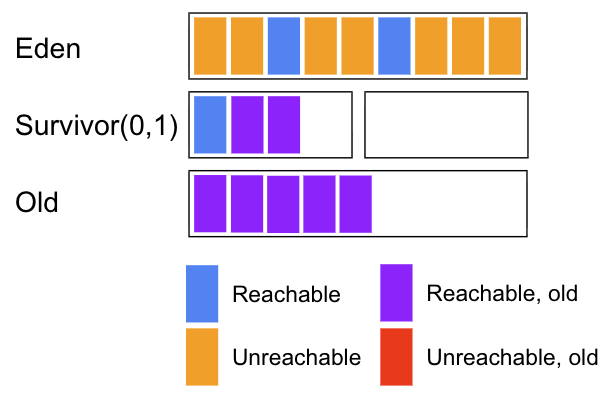
보통 힙공간의 메모리는 순차적으로 메모리 공간을 사용하기 때문에 중간중간에 해제된 메모리 영역은 메모리가 해제되었지만 사용 할 수가 없다. 이를 단편화라 하며, 단편화를 해결하기 위해 Compact 단계가 있다.
한계
Serial GC는 알고리즘이 단순하여 이해하기는 쉽지만 프로덕션에서는 잘 사용하지 않는다. 가장 큰 단점은 GC를 싱글 쓰레드로 수행하기 때문에 STW 시간이 길어 성능에 이슈가 있기 때문이다.
Parallel GC
Serial GC의 단점을 해결하기 위해 멀티 쓰레드 방식으로 GC를 처리하는 Parallel GC가 도입되었다. Parallel GC는 Serial GC와 동작 방식은 같지만 GC 동작을 멀티쓰레드로 처리하기 때문에 Copy나 Mark-Sweep-Compact 과정을 더 빠르게 진행할 수 있어서 STW 시간이 줄어든다.

Serial VS Parallel
Serial GC와 Parallel GC가 성능적으로 얼마나 차이가 나는지 테스트해보기 위해 테스트 코드를 작성하여 직접 성능비교를 해보았다.
예제 코드
WebServer
Spring Boot를 사용하여 간단한 웹서버를 구현하였다. GET /test 요청을 라우팅하는 Router와 해당 요청을 핸들링하는 Handler를 구성하였다.
@Configuration
class MainRouter (
private val mainHandler: MainHandler
) {
@Bean
fun mainRoute(): RouterFunction<ServerResponse> {
return router {
accept(MediaType.APPLICATION_JSON).nest {
GET("/test", mainHandler::test)
}
}
}
}package org.example.handler
import org.example.data.Data
import org.springframework.beans.factory.annotation.Value
import org.springframework.stereotype.Component
import org.springframework.web.reactive.function.server.ServerRequest
import org.springframework.web.reactive.function.server.ServerResponse
import org.springframework.web.reactive.function.server.ServerResponse.ok
import org.springframework.web.reactive.function.server.bodyValueAndAwait
import reactor.core.publisher.Mono
import java.util.concurrent.ArrayBlockingQueue
import java.util.concurrent.ConcurrentLinkedQueue
import java.util.concurrent.atomic.AtomicLong
import kotlin.random.Random
@Component
class MainHandler(
@Value("\${queue.size}") private val size: Int
) {
private val queue = ConcurrentLinkedQueue<Data>()
val index = AtomicLong(0L)
fun test(request: ServerRequest): Mono<ServerResponse> {
val youngData = Data(index.get(), Random.nextBytes(2048))
val oldData = Data(index.incrementAndGet(), Random.nextBytes(2048))
// 큐 사이즈 제한을 수동으로 처리
if (queue.size >= size) {
queue.poll() // 오래된 데이터 제거
}
queue.offer(oldData) // 블로킹 없이 추가
val firstNumber = queue.firstOrNull()?.number ?: -1
val lastNumber = queue.lastOrNull()?.number ?: -1
return ok().bodyValue(TestResponse(oldData.number, queue.size, firstNumber, lastNumber))
}
}
data class TestResponse(val index: Long, val queueSize: Int, val first: Long, val last: Long)
data class Data(
val number: Long,
val content: ByteArray,
)- ConcurrentLinkedQueue를 사용하여 오래 머무를 객체를 저장하는 큐를 구성하였다. 큐에 있는 객체는 old로 승격이 될 확률이 높다.
- oldData는 큐에 저장될 객체를 참조한다.
- youngData는 쓰레드에서 선언하였고, 큐와 같은 곳에 저장이 되지 않기 때문에 단기에 소멸될 객체이다.
Pod
테스트용 애플리케이션을 쿠버네티스에 띄우고, 다음과 같이 구성하였다. 예시는 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
name: jvm-test-559f87c9d6-4m6tr
namespace: test
spec:
containers:
- env:
- name: JAVA_TOOL_OPTIONS
value: |
-XX:+AlwaysPreTouch -XX:+ExitOnOutOfMemoryError
-XX:InitialRAMPercentage=50 -XX:MinRAMPercentage=50 -XX:MaxRAMPercentage=50
-XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=64m
-XX:+UseParallelGC
- name: QUEUE_SIZE
value: "262144"
image: beer1/jvm-test:dev
imagePullPolicy: Always
name: jvm-test
ports:
- containerPort: 8080
name: http
protocol: TCP
resources:
limits:
memory: 2Gi
requests:
cpu: "0.5"
memory: 2Gi- Queue size는 256 * 1024 개로, 큐가 꽉 차면 대략적으로 2MB 이상 차지한다.
- 힙 사이즈는 1Gi 로 할당하였다.
-XX:+UseParallelGC또는-XX:+UseSerialGC를 사용하여 GC 알고리즘을 선택할 수 있다.
테스트 요청 스크립트
테스트 요청 스크립트는 python으로 작성하였고 단순히 10만번 GET /test를 요청하는 스크립트이다.
import requests
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def call():
headers={
'User-Agent': 'python-requests/2.31.0',
"Connection": "close"
}
try:
response = requests.get("http://test-app.beer1.com/test", headers=headers)
time.sleep(0.05)
return True
except Exception as e:
return False
if __name__ == "__main__":
start = datetime.now()
total_requests = 200000
max_workers = 16 # 동시에 실행할 스레드 개수
succeeded = 0
failed = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 요청 작업들을 스레드풀에 제출
futures = [executor.submit(call) for _ in range(total_requests)]
for i, future in enumerate(as_completed(futures), start=1):
result = future.result() # 필요하면 결과 처리
if result:
succeeded += 1
else:
failed += 1
if i % 10000 == 0:
print(f"[{datetime.now()}] ({total_requests - i} 개 남음, 성공: {succeeded}, 실패: {failed})")
end = datetime.now()
print(f"[{end}] Request completed, elapsed time: {end - start}")- 16개의 쓰레드풀을 사용하여 병렬처리
- 총 20만번 호출
- 20만 * 2048 byte = 약 390MB 정도가 Old에 머무를 예정
결과
일단 다음과 같은 스펙으로 Serial GC와 Parallel GC를 비교한 결과는 다음과 같다.
- CPU: 제한 없음. (최대 10코어)
- 힙메모리: 약 1Gi
- 큐 사이즈: 256K
먼저 Serial GC에서는 17분 56초가 걸렸다.

Serial GC에는 Major GC는 발생하지는 않고 Minor GC만 발생했다. 평균 GC STW는 12.1ms 정도로 측정되었고 (GC pause seconds Last), 총 GC는 20번 발생했다.

Parallel GC에서는 14분 42초가 걸렸다.
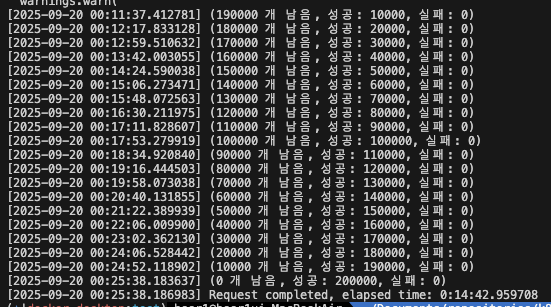
Parallel GC 또한 Major GC는 발생하지는 않고 Minor GC만 발생했다. 평균 GC STW는 8.43ms 정도로 측정되었고 (GC pause seconds Last), 총 GC는 40번 발생했다.
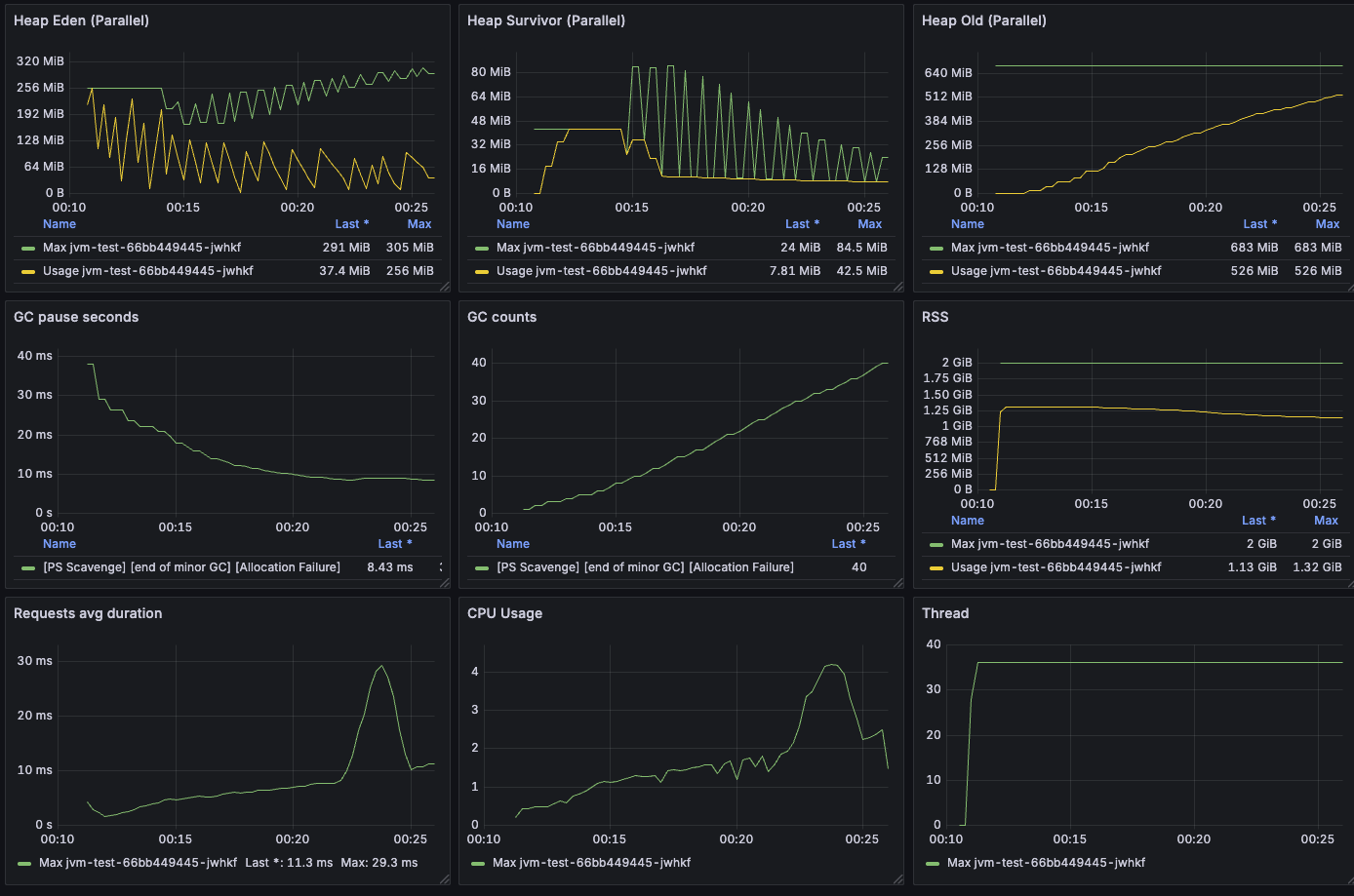
GC는 Serial보다 더 많이 발생했지만 STW가 짧아서 그런지 20만번 호출 결과 Parallel이 3분정도 더 빨랐다.
'[개발] Java & Kotlin' 카테고리의 다른 글
| JVM GC에 대해 알아보자. (G1GC) (0) | 2025.09.21 |
|---|

댓글